

BaiduのPaddleOCRを動かしてみました。
今回はGPU(RTX 2080 Ti)との精度比較、実行速度、そして日本語OCRにおける実運用目線の課題を確認しました。
検証環境と前提
- AIアクセラレータ:DEEPX DX-M1(25TOPS)
- 比較対象GPU:NVIDIA GeForce RTX 2080 Ti
- OCRエンジン:Baidu PaddleOCR
- テストデータ:日本語テキスト画像
- 実行環境:DEEPX社提供デモソフト
評価は主に、精度差・1枚あたりの推論時間・認識結果の質の3点で行いました。
テスト結果
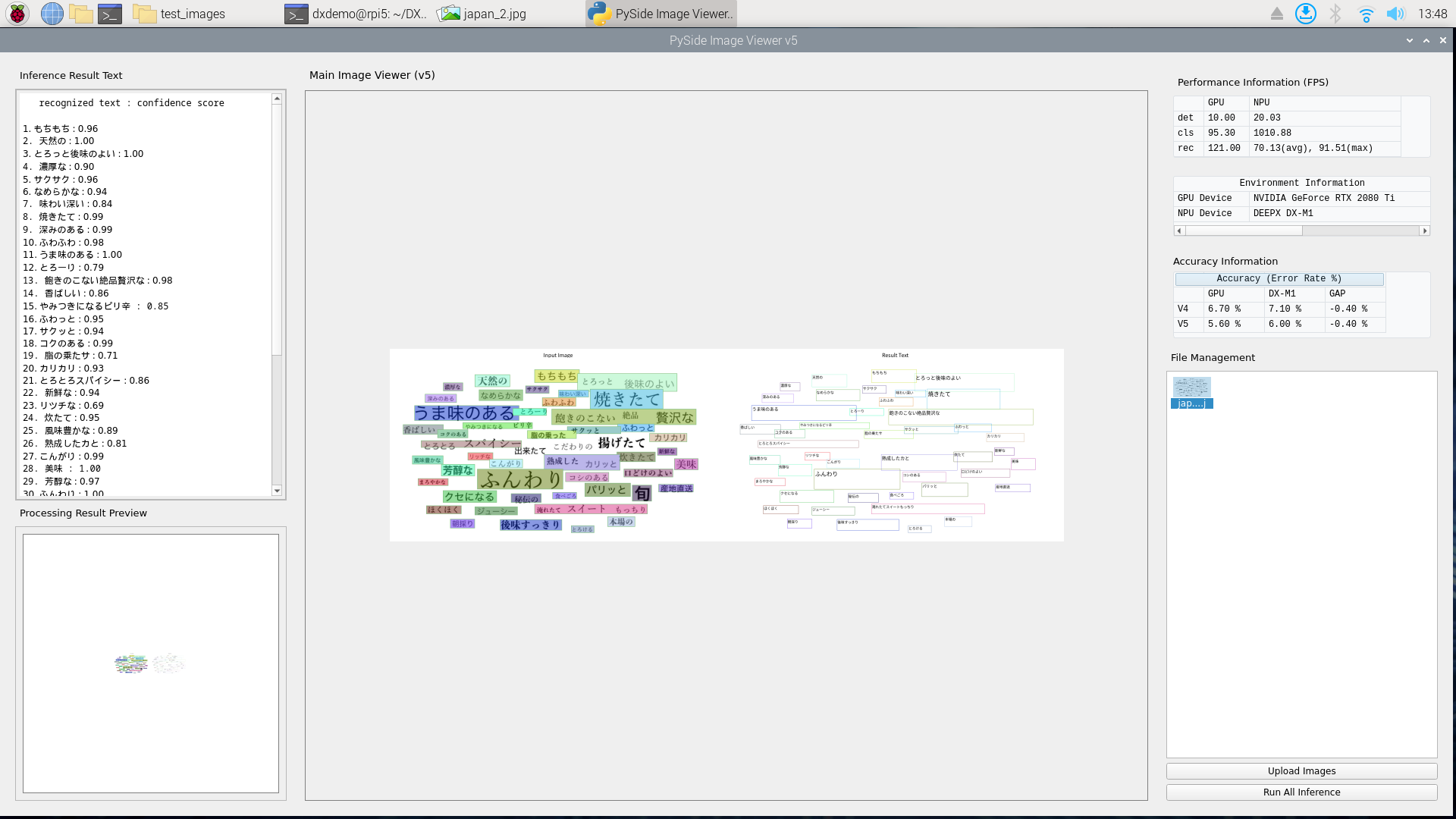
サマリー:DX-M1でOCRは“実用に近い”が、日本語はまだ伸びしろあり
- 精度差:RTX 2080 Tiとの差は 約0.4% と小さい
- 速度:1画像あたり 約1.5秒 で処理でき、体感でも十分高速
- 課題:日本語画像では取りこぼしがあり、完全認識には未達
精度評価:GPUとの差は約0.4%
デモ画面上の比較情報から、DX-M1とRTX 2080 Tiの精度差は約0.4%に収まっており、
全体としては非常に健闘している印象です。
エッジ向け(低消費電力)デバイスとして考えると、ここまでGPUに近い精度が得られるのは大きなメリットだと思います。
特に、クラウド依存を下げたいケース(工場内端末、店舗内分析、ネットワーク制約環境)では、
このレベルの精度差であれば導入判断がしやすいと思います。
速度評価:1枚あたり約1.5秒は実運用に乗せやすい
OCR処理時間は約1.5秒/画像。
バッチ用途や定期スキャン用途では十分実用的で、オンデバイスで完結できる利点(遅延・通信コスト・プライバシー面)も活かしやすいです。
さらにDX-M1は約3Wの省電力動作が可能なため、常時稼働が必要なエッジ機器との相性が良い構成と言えます。
認識品質の観察:低スコア項目と未検出が見える
スクリーンショットのInference Result Textを見ると、項目ごとにconfidenceが表示されており、
一部にスコアの低い候補が存在しています。
また、目視ベースでは文字の検出自体ができていない箇所も見受けられました。
つまり、今回の結果は「高速で高効率」な一方で、日本語OCRとしては完璧ではないという評価です。
なぜ日本語で取りこぼしが出るのか(考察)
今回の結果から推測される主因は、無償提供されているPaddleOCRの日本語チューニング不足ではないかと考えています。
PaddleOCR自体は非常に有用なOSSですが、実案件レベルでは以下の要素が精度を左右するのではないでしょうか。
- 日本語フォント・字種(ひらがな/カタカナ/漢字/記号)の学習カバレッジ
- 印刷品質や背景ノイズに対するロバスト性
- 小文字・低コントラスト領域の検出閾値最適化
- ドメイン固有語彙(商品説明・業界用語)への対応
したがって、DX-M1のハード性能そのものよりも、モデル/辞書/前処理の最適化で
まだ改善余地が大きいと考えられます。
最後に
DEEPX DX-M1は、25TOPS / 約3Wという優れた電力性能比を持ちながら、
OCRタスクでもGPUとの差約0.4%という高い実力を示しました。
処理速度も約1.5秒/画像と速く、エッジ展開を見据えた選択肢として十分有望です。
一方で、日本語に関しては認識漏れや低confidenceが残っており、現時点では
「そのまま完璧」ではなく「改善前提で実用可能」というのが率直な結論です。
モデル最適化と運用設計を組み合わせれば、さらに実務で使いやすいOCR基盤へ引き上げられるはずです。
DX-M1にご興味の方は三信電気までご気軽にお問い合わせください。







